深入探讨日文编码系统与乱码关系解析及其应对策略
在当今数字化信息交流日益频繁的时代,语言编码系统的重要性不言而喻。特别是对于日文这样具有独特字符和书写体系的语言,其编码系统的复杂性可能导致在信息处理和传输过程中出现乱码问题。理解日文编码系统与乱码之间的关系,并制定有效的应对策略,对于保障信息的准确传递和正确显示至关重要。
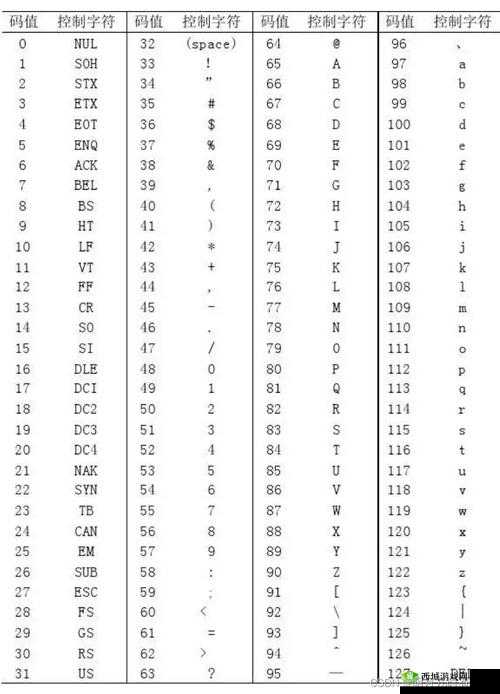
日文编码系统的多样性是导致乱码问题的一个重要因素。常见的日文编码方式包括 Shift_JIS、EUC-JP 和 UTF-8 等。Shift_JIS 是日本早期广泛使用的编码标准,但它在处理一些特殊字符和汉字时可能存在局限性。EUC-JP 则在一定程度上改善了对汉字的支持,但仍然可能在特定环境下产生兼容性问题。而 UTF-8 作为一种通用的字符编码标准,具有更广泛的兼容性和对多语言的良好支持,但如果在处理日文时没有正确设置或转换编码,也容易出现乱码。
乱码产生的原因多种多样。一方面,不同的操作系统、应用程序和数据库可能默认使用不同的日文编码方式。当数据在这些不同的环境之间交换时,如果没有进行正确的编码转换,就会导致乱码的出现。例如,一个使用 Shift_JIS 编码保存的日文文件,在一个默认使用 UTF-8 编码的系统中打开,很可能会显示为乱码。网络传输过程中的错误或不完整的数据传输也可能导致编码信息丢失或损坏,从而引发乱码问题。
当我们面对日文乱码时,首先需要确定乱码所使用的编码方式。可以通过查看相关的文件属性、应用程序设置或借助专门的编码检测工具来获取编码信息。一旦确定了编码方式,就可以进行相应的转换操作。许多现代的文本编辑工具和编程语言都提供了编码转换的函数和方法,能够将一种编码的文本转换为另一种编码。
为了有效预防日文乱码问题的出现,我们需要在软件开发和系统配置中采取一系列措施。在软件开发过程中,应始终遵循最佳实践,使用统一且广泛支持的编码标准,如 UTF-8。在数据存储和传输时,明确指定编码方式,并在需要转换编码的地方进行正确的处理。对于用户输入的日文内容,进行严格的编码验证和纠错处理,以确保数据的完整性和正确性。
在系统配置方面,确保操作系统、数据库和应用程序的编码设置一致且支持所需的日文编码方式。对于服务器端的配置,要根据服务的受众和应用场景,合理设置默认的编码格式,并提供编码转换的接口和功能,以满足不同用户和客户端的需求。
加强对用户的教育和培训也是非常重要的。让用户了解编码的基本概念和常见的乱码问题原因,以及如何正确处理和避免这些问题。例如,教导用户在保存和发送日文文件时注意选择正确的编码方式,避免在不同编码环境之间随意复制粘贴文本等。
深入理解日文编码系统与乱码之间的关系,并采取有效的应对策略,是保障日文信息在数字化世界中准确、流畅传递和显示的关键。这不仅需要技术层面的支持和改进,还需要用户意识的提高和规范操作的养成。只有通过多方面的努力,我们才能有效地解决日文乱码问题,促进跨语言信息交流的顺畅进行。
随着技术的不断发展和创新,新的挑战和机遇也将不断涌现。例如,移动设备的普及和云计算的应用,对日文编码的处理提出了更高的要求。在未来,我们需要持续关注技术的发展趋势,不断优化和完善我们的编码处理策略,以适应不断变化的信息处理环境。
国际间的合作和标准的统一也将对解决日文编码问题起到积极的推动作用。通过与国际标准化组织和其他国家的技术交流与合作,共同制定更加完善和统一的编码标准和规范,将有助于减少因编码差异而导致的乱码问题,促进全球范围内的信息共享和交流。
人工智能和自然语言处理技术的发展也为解决日文乱码问题提供了新的思路和方法。利用机器学习算法和语言模型,可以对乱码进行自动检测和修复,提高编码处理的效率和准确性。
在教育领域,应进一步加强对编码技术和多语言信息处理的教学,培养更多具备相关专业知识和技能的人才。他们将为解决日文编码问题以及推动信息技术的发展做出重要贡献。
解决日文编码系统与乱码的问题是一个长期而复杂的过程,需要技术、标准、教育和合作等多方面的协同努力。只有这样,我们才能更好地应对未来的挑战,实现更加高效和准确的日文信息处理和交流。